Index란?
RDBMS에서 대용량의 데이터(레코드)가 있을 때, 특정 데이터를 검색하기 위해서 테이블의 레코드를 full scan하는 것이 아니라, 인덱스가 적용된 컬럼의 테이블(컬럼, 인덱스주소)을 따로 파일로 저장해놓고 그것을 검색해서 검색 효율을 높이는 방법
사실 여기까지만 알고 그다지 깊게 알지 못했는데, 면접 때 구체적인 걸 물어보셔서 대답하지 못했던 부분이다.
좀 더 자세히 살펴보도록 하자.
범위 스캔 Range Scan
인덱스는 key column순으로 정렬되어 있기 때문에, 특정 값을 찾다가 해당 범위를 벗어나는 값을 만나면 멈춘다.
(그러면 그 이전 값과 벗어났던 값 사이에 있다는 의미이므로)
인덱스 테이블 파일은 B-tree로 주로 표현한다
B-tree란?
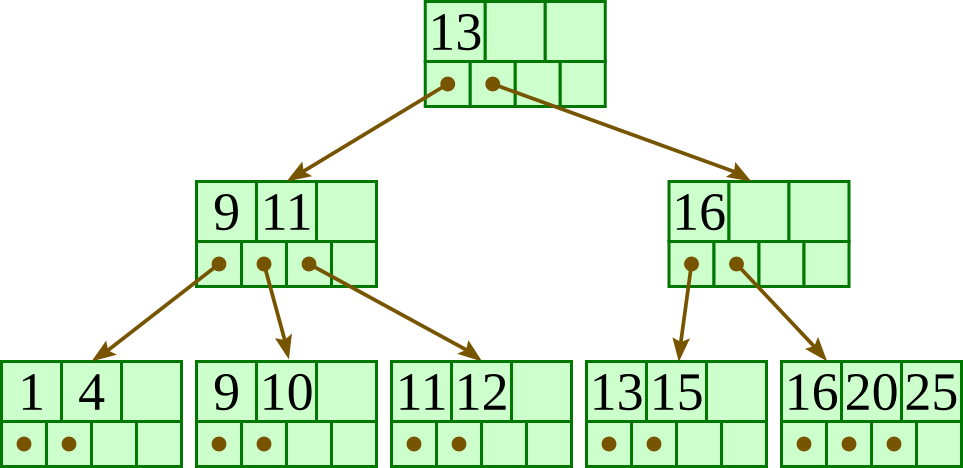
- root block, branch block, leaf block으로 구성된다.
- leaf block의 깊이가 모두 동일한 트리이다.
- 그러므로, B의 의미가 Balanced Tree라는 의미라고 볼 수 있다. (창시자의 오피셜은 아니다)
탐색하는 방법에서 예를들면, 만약 SQL문에 between 10 and 20 이라는 조건이 있었을 때
- 최소값인 10을 기준으로 찾은 후에 해당 노드에서 값을 찾고(ex. 15, 17, ...)
- 만약 20이 해당 노드에 없으면 부모노드로 올라가서 20이 있는지도 검사하게 된다.
- 20보다 큰 인덱스 값이 있다면 범위 검색을 멈춘다.
- B-tree가 정렬이 된 상태로 유지하기 때문에 그 이상의 값은 무의미 하다.
좀 더 구체적으로, 찾고자 하는 값이
- branch block에서 가장 왼쪽 값보다 작거나 같을 때는 왼쪽 포인터
- branch block 사이에 있으면 사이 포인터
- branch block에서 가장 큰 값보다 크면 오른쪽 포인터
로 찾아간다.

위의 그림에서 7보다 작은 값에 대해서는 왼쪽 포인터, 7과 16 사이의 값에 대해서는 사이 포인터, 16보다 큰 값에 대해서는 오른쪽 포인터로 찾아가면 된다는 것을 알 수 있다.
Index는 언제 적용해야 좋을까?
Good : SELECT문의 WHERE, JOIN
Bad : INSERT, UPDATE, DELETE
INSERT할 때의 문제
- 새로운 데이터를 삽입하면서 테이블에 record를 넣어줄 뿐만 아니라, 인덱스 테이블에도 정보를 업데이트 해야 한다.
- 만약, leaf block이 꽉 찼는데 그 사이에 값을 추가해야 한다면 다른 block으로 밀려나야할 데이터가 생기고, 이렇게 되면 새로운 블럭에 key를 옮길 때 모든 과정이 redo에까지 기록되는 수고 생긴다.
DELETE할 때의 문제
- 기존 테이블에서는 그냥 record를 삭제하고 그 공간을 다른 record가 사용할 수 있게 하지만,
- 인덱스 테이블에서는 사용안함 표시만 하고 자리를 그대로 차지한다.
UPDATE할 때의 문제
- UPDATE는 내부적으로 DELETE한 뒤 INSERT하는 방식이라 두 방식의 오버헤드가 모두 생긴다.
Good : 날짜 (나올 수 있는 값이 매우 다양하고 고르며, 거의 유일함)
Bad : 성별 (0.5로 나뉨)
성별같이 거의 반반으로 나뉘는 경우는 어차피 모조리 다 찾아야 하기 때문에 효율적이지 않다.
이런 경우에는 bitmap index를 사용하는 것이 좋다. 물론, bitmap index를 사용하면 컬럼을 추가할 경우 bitmap index의 모든 map을 수정해야하는 큰 문제가 생긴다.
결론
1. SELECT의 사용이 잦고, INSERT, UPDATE, DELETE 문이 적게 일어나는 테이블에서 인덱스를 사용해야 좋다.
2. 인덱스 컬럼의 분포도가 좋을 때 효율적이다.
그 외 Index 적용 시 유의 사항
- 인덱스 key column은 가능하면 작게 설계
- 단일 인덱스 여러 개를 사용해야 할 경우에는 다중 컬럼 인덱스 생성을 고려
- 되도록 동등비교(=) 사용
- 인덱스 컬럼은 변경하면 안되므로, 함수나 수식을 적용하면 안된다.
- 대신 비교하는 값에 column에 맞도록 함수나 수식으로 값을 변환하여 비교한다
SELECT column_name FROM table_name WHERE TO_CHAR(column_name, 'YYYYMMDD') = '20180101';
# 수정
SELECT column_name FROM table_name WHERE column_name = TO_DATE('20180101','YYYYMMDD');
SELECT column_name FROM table_name WHERE column_name * 100 > 10000;
# 수정
SELECT column_name FROM table_name WHERE column_name > 10000 / 100;
- 내부 형변환이 없도록 타입을 맞춰주며 사용해야한다.
SELECT column_name FROM table_name WHERE column_name = '20180101'; // column이 DATE타입
# 수정
SELECT column_name FROM table_name WHERE column_name = TO_DATE('20180101','YYYYMMDD');
SELECT column_name FROM table_name WHERE column_name = 100; // column이 문자타입
# 수정
SELECT column_name FROM table_name WHERE column_name = '100'; - 조건 절에 NULL, NOT NULL을 사용하면 성능이 좋지 않다. (원래 DB 설계 시에 NULL을 허용하지 않는 것이 좋다.)
SELECT column_name FROM table_name WHERE column_name IS NULL;
# 수정
SELECT column_name FROM table_name WHERE column_name > '';
SELECT column_name FROM table_name WHERE column_name IS NOT NULL;
#수정
SELECT column_name FROM table_name WHERE column_name >= 0;
- !=, NOT 같은 부정형 조건을 사용하면 성능이 좋지 않다.
SELECT column_name FROM table_name WHERE column_name != 30;
# 수정 방안 1
SELECT column_name FROM table_name WHERE column_name < 30 AND column_name > 30;
# 수정 방안 2
SELECT column_name FROM table_name WHERE NOT EXISTS
(SELECT column_name FROM table_name WHERE column_name = 30);- LIKE연산자를 사용할 때 앞에 %를 넣으면 성능이 좋지 않다.
SELECT column_name FROM table_name WHERE column_name LIKE '%문자%';
# 아래와 같이 수정
SELECT column_name FROM table_name WHERE column_name LIKE '문자%';
- OR 조건을 사용하면 성능이 좋지 않다.
SELECT column_name
FROM tbl1 t1, tbl2 t2
WHERE (t1.col1 = t2.col1 OR t1.col2 = t2.col2) AND t1.col3 = 'value';
# 아래와 같이 수정한다.
SELECT column_name
FROM tbl1 t1, tbl2 t2
WHERE t1.col1 = t2.col1 AND t1.col3 = 'value'
UNION ALL
SELECT column_name
FROM tbl1 t1, tbl2 t2
WHERE t1.col2 = t2.col2 AND t1.col3 = 'value';
References
'CS > DB' 카테고리의 다른 글
| [데이터베이스] 트랜잭션 ACID (0) | 2019.10.27 |
|---|---|
| [데이터베이스] 격리성 관련 문제와 격리성 수준 (Isolation Level) (0) | 2019.10.24 |