Accuracy (정확도)
정확한 예측을 한 비율. (맞게 분류한 수) / (전체 데이터 수)
accuracy에는 함정이 있다.
만약 0~9의 10개의 숫자를 분류하는 문제가 있다고 했을 때, 하나의 숫자마다 데이터에 10%씩 존재한다고 하자.
이 때, 5인지 아닌지를 판별하는 이진 분류기를 만드려고 한다.
별 다른 학습 없이 무조건 5라고 판별하는 분류기, 무조건 5가 아니라고 판별하는 분류기를 만들었다고 해본다면,
- 무조건 5라고 판별하는 분류기의 정확도는 10%
- 무조건 5가 아니라고 판별하는 분류기의 정확도는 90%
후자의 경우엔 언뜻 성능이 좋아보일 수 있다.
하지만 이는 그저 데이터의 쏠림에 기인한 것일 뿐, 5가 50%의 비율로 존재하는 셋이라면 전혀 다른 결과가 나온다.
이처럼 데이터의 쏠림에 의해 정확도는 실제 성능과 관계없는 수치를 뽑아낼 수도 있기 때문에, Precision과 Recall까지 고려하게 된다.
Precision (정밀도)
얼마나 정확하게 분류하는지 => Positive로 분류한 것들 중에 실제로 Positive한 비율
Recall (재현율)
Positive에 대해 얼마나 많이 분류하는지 => 실제 Positive 중에 Positive로 판별한 비율
= Sensitivity(민감도), TPR(True Positive Rate)

Precision과 Recall에 대해 학교에선 이런 이미지로 배웠었는데, 그닥 직관적이지 않아서 단번에 떠올리기는 좀 힘들었다.
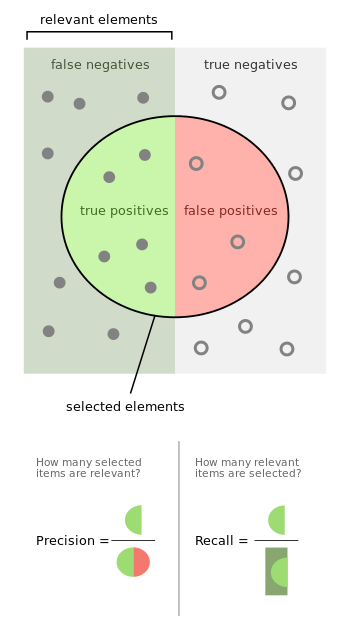
이 이미지를 떠올리면 좀 더 쉽게 기억된다.
F1 score
precision과 recall의 조화 평균이다.

실제 머신러닝/딥러닝 문제에선?
precision과 recall은 trade-off 관계에 있다. 따라서 어떤 하나를 더 높게 가져가려면, 다른 건 조금 포기해야 하는 부분이 생긴다.
이를 염두에 두고 적절한 수준에서 모델을 결정해야 하는데, 이건 현실 상황의 문제에 맞추어 판단하면 된다.
암을 판별하는 것에선 precision이 높기 보단, 최대한 놓치지 않고 모든 암을 판별하는게 중요하기 때문에 recall을 좀 더 중요하게 생각해야 한다.
경비 시스템에서도 마찬가지로, 모든 도둑을 잡아야하기 때문에 recall이 중요할 것이다.
반면, 아이들에게 유해한 콘텐츠를 차단하는 문제에선 정말 잘 차단하는 것이 중요하기 때문에, 다른 유해하지 않은 콘텐츠들을 좀 놓치는 걸 감수하더라도 precision을 높여야할 것이다.
출처
- Hands On Machine Learning
- https://ko.wikipedia.org/wiki/%EC%A0%95%EB%B0%80%EB%8F%84%EC%99%80_%EC%9E%AC%ED%98%84%EC%9C%A8
- en.wikipedia.org/wiki/F-score